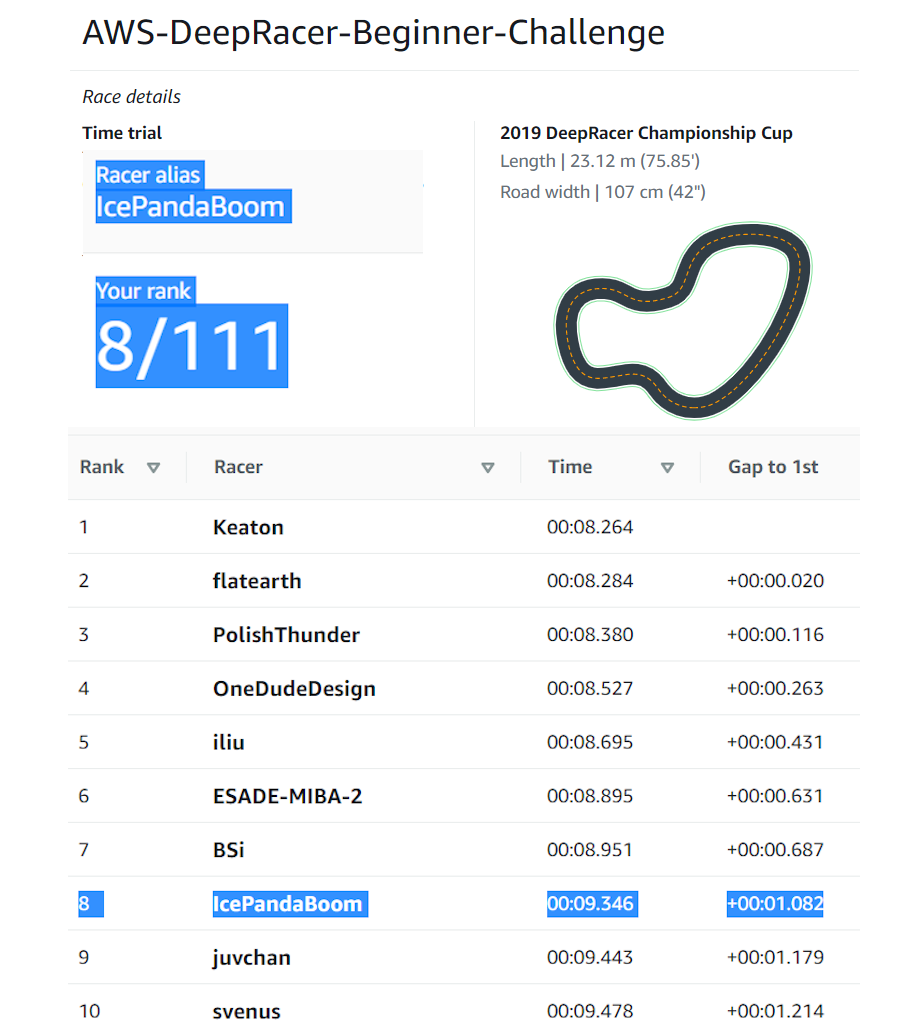
Breaking in to the Top 10 of AWS Deepracer Competition - May 2020
As a F1 buff, I came across the AWS Deepracer May 2020 promotional event and couldn't pass on the challenge to pit myself against the ever smiling 7-time F1 race winner Daniel Ricciardo. This article chronicles my 2.5 week journey from a complete AWS Deepracer newbie to placing top 10 of the Beginner Challenge competitive leaderboard. Part 1 of this blog series I'll discuss how I overcame the AWS Deepracer learning curve and present a robust reward function. In Part 2 I will be sharing my insights on how to break into the top 10 of the leaderboard by using waypoints, and also quantifying the training using the log analysis tools.
Accelerating Through the Learning Curve
After training the Original Deepracer model that everyone starts out with, I realised that to be competitive the model needs speed and stability. Scavenging the internet for any piece of hidden gem that I could uncover, I found the the following was crucial to overcome the steep learning curve in a short period of time:
- Completing the AWS Deepracer online course
- Understanding the Deepracer documentation
- Joining the Deepracer Community
- Scavenging online for reward functions
- Reading a eye opening reinforcement learning (RL) articles
In the month of May there were many events running - 3 different race modes and 2 different tracks. From my initial experimentations in model training, I observed that I needed at least 6 hours to train a stable model (which turned out to be an underestimate when training with higher speeds). I made an executive decision early on to only train for the time trials race mode. Also since the Summit Online and Beginner-Challenge events were both run on the reInvent2019 track I opted to put my initial focus on this shorter track.
Reward Function, Action Space and Hyperparameters
First few days were mainly trial and error. My first major realisation was that rather than the default step function centerline reward, the reward function needed to be more granular. Due to the random exploration nature of the training, a continuously sloping reward function pushes the model towards the desired behaviour much faster.
The reward function below is designed for self exploration and is good enough for the upper quartile of the leaderboard.
Click to expand reward function
#Optimise for efficient progress and speed
def reward_function(params):
# Read input variables
reward = 0.001
if params["all_wheels_on_track"]:
if params['steps']<10:
reward = (1 - (params['distance_from_center'] / (params['track_width']/2))**(4))*params['speed']**2
if params['steps']>=10:
reward = ((params['progress']*params['speed']**2)/params['steps'])*2
else:
reward = 0.01
if abs(params['steering_angle']) < 10 and params['speed']==3:
reward += params['speed']**2/4
else:
reward += 0.01
return float(reward)
The reward function aims to:
- Initially promote the model to be on the centerline
- After 10 steps reward is given based on efficient track completion (progress/steps) and speed
- Without fixating on the centerline, the model is allowed to explore the track to find a more optimal line by itself (cutting corners, hitting apexes)
- The last if-statement in the is to sensitize the model to high speed straight line driving
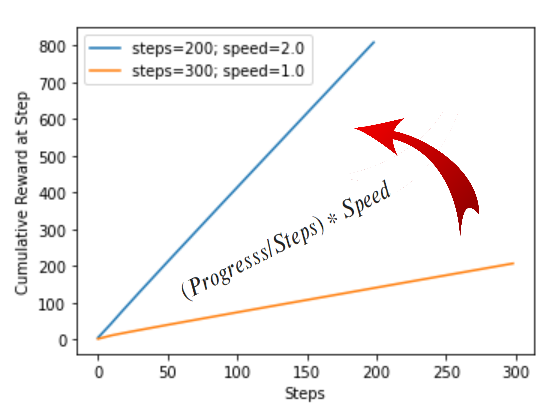
The graph above shows the ideal training behaviour of the reward function. The idea is that since reaching the finish line with smaller number of steps and higher speeds gives it more reward, the model will progressively find a more efficient driving line and take it with highest speed possible.
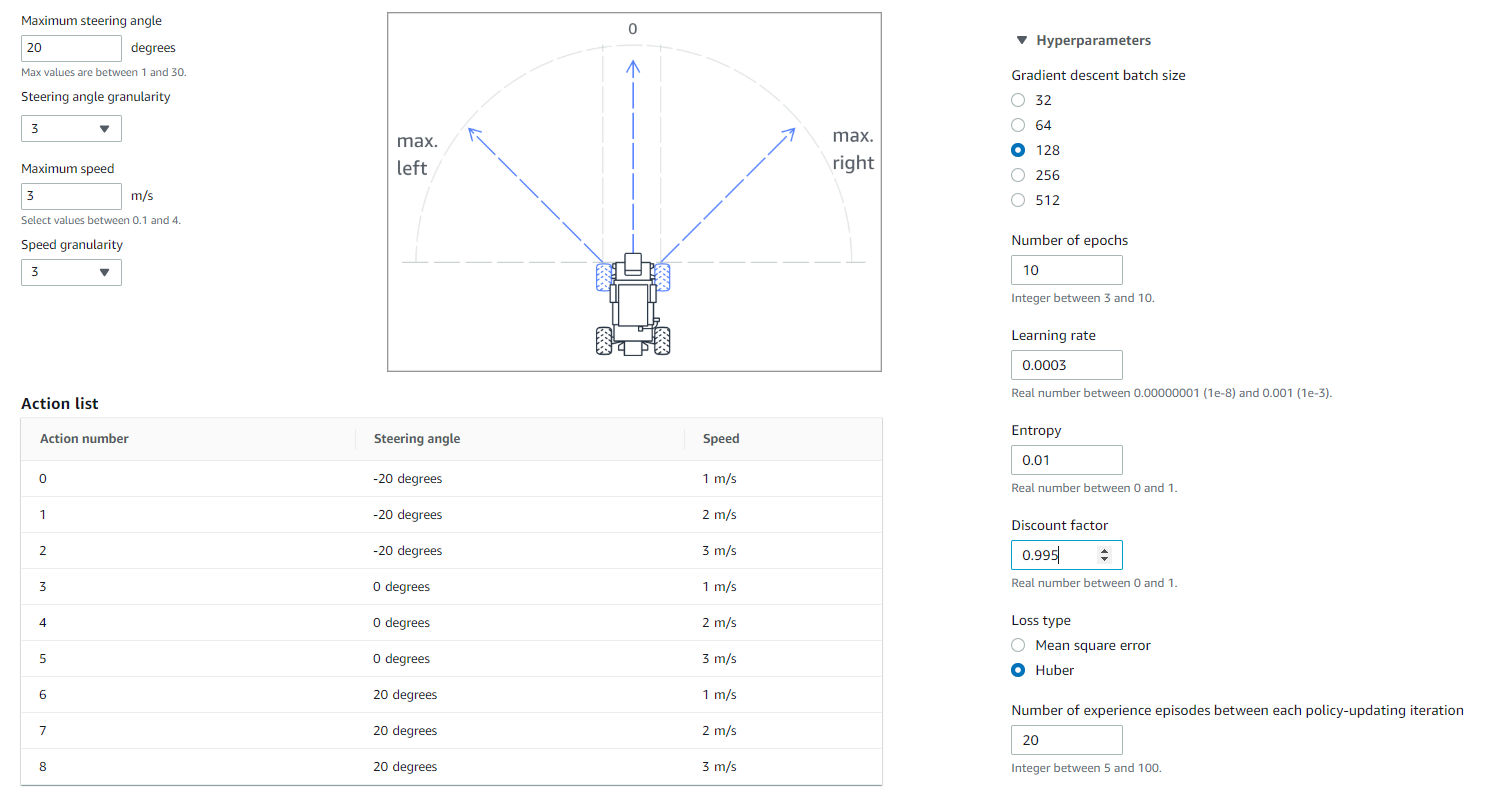
Action space and hyperparameters are also important, as too many possible actions and wrong hyperparameters can lead to slow learning. For the reInvent2019 track I opted for the following:
- 3-layer-CNN for fast training
- Speeds ranges (1,2,3)
- Turning angles (-20,0,20)
- Hyperparameter Batch size 128
- Hyperparameter Discount factor 0.995
I could have chosen higher speeds (1.33,1.67,4.0) but the car becomes harder to train and unwieldy due to the sliding physics in the Gazebo training environment. A 1/18th car model with 4m/s translates to a full sized car speeding at 259km/h.
The following quote is quite accurate for my Deepracer journey: "It's useful to imagining deep RL as a demon that's deliberately misinterpreting your reward and actively searching for the laziest possible local optima." For Deepracer, this means for the model to find the best racing line just by random exploration is almost like a monkey with a typewriter eventually writing Shakespeare. The fastest time I found possible with the above set of parameters was 14s for the reInvent2019 track. To get into the top 10, a consistent sub 10s track completions is needed. The only efficient way to do this is to delve into the controversial issue of overfitting the model to the track.
In the next part of this blog I will share how to break into the leaderboard top 10 with my implementation of the racing line using waypoints. Click here for Part 2.